Spark Summit, le retour
Le Spark Summit - la conférence officielle autour du framework Apache Spark - se tenait à Amsterdam du 27 au 29 octobre. Votre serviteur était présent les 28 et 29 octobre. Résumé des évènements.
Quelques faits
Cette conférence était le premier Spark Summit organisé en Europe, les précédents ayant eu lieu à San Francisco et New York. 930 participants étaient réunis pour 2 jours de conférence et, pour certains, un jour supplémentaire de training.
Les conférences étaient réparties entre 4 tracks : développeur, applications, Data Science et recherche. La plupart du temps, seuls deux tracks étaient menés en parallèle ce qui permettait d’assister à près de la moitié des talks.


Les conférences étaient en format 30 minutes, format sur lequel j’ai un avis partagé. D’un côté, les sessions sont suffisamment courtes pour qu’on puisse choisir un talk sans avoir peur de se tromper. De l’autre, et c’est plus gênant, les speakers ne disposaient pas d’assez de temps pour rentrer dans les détails techniques.
Les tendances de fond
Importance croissante de la Data Science
À en juger par le public (nombreux Data Scientists) et par le programme (track Data Science), Spark est populaire notamment grâce à sa librairie de Machine Learning. Les talks portant sur ce sujet ont été nombreux, à commencer par une démo de Sentiment Analysis avec Databricks Cloud par Hossein Falaki, dont je recommande la vidéo.

Full streaming, Akka, Cassandra…
La tendance est au streaming plutôt qu’au batch, et donc à un traitement des évènements au fur et à mesure de leur arrivée plutôt que de faire tourner des process à intervalles réguliers. De nombreux speakers ont mentionné Kafka pour stocker le flux d’évènements et le processer ensuite avec Spark Streaming.
Par ailleurs, Cassandra a été mentionné de nombreuses fois (et pas uniquement par Patrick McFadin !) comme étant une base de données parfaitement adaptée pour supporter des workloads importants.
Plus généralement, c’est la stack SMACK (Spark, Mesos, Akka, Cassandra, Kafka) qui semble avoir les faveurs de nombreux développeurs plutôt que des stacks reposant sur Hadoop.
Dans l’idée d’utiliser le streaming, plusieurs voix se sont élevées pour abandonner la définition actuelle des ETL. La notion d’“Extract” est dépréciée, car on reçoit désormais des flux (qui plus est contenant des données typées). Il en va de même pour la notion de “Load”, puisque les données transformées sont désormais consommées par plusieurs systèmes. Une définition alternative est proposée : CTP (Consume, Transform, Produce).




Je recommande les talks d’Helena Edelson, Lambda Architecture, Analytics and Data Pathways with Spark Streaming, Kafka, Akka and Cassandra, et de Natalino Busa, Real-Time Anomaly Detection with Spark ML and Akka.
Popularité des langages
Côté développeurs, Scala était clairement le langage adopté par le plus grand nombre. Typesafe était d’ailleurs présent et représenté par Martin Odersky (voir sa keynote).
Côté Data Science, R et le binding Spark R étaient largement présents dans les talks. Voir notamment le talk d’Hossein Falaki, Enabling exploratory data science with Spark and R. Python, bien que beaucoup utilisé, était finalement moins représenté dans les talks.


Clusters à la demande
Chez Databricks - avec Databricks Cloud - comme chez Goldman Sachs, les clusters Spark sont lancés à la demande. Le point surprenant est que la data locality n’est pas possible, puisque les données sont stockées sur un datastore permanent (S3 dans le cas de Databricks Cloud). Néanmoins, chez Goldman Sachs, cela permet aux Data Scientists d’utiliser des clusters de processing sur de courtes durées pour un coût réduit.
Je recommande d’ailleurs l’excellente keynote de Vincent Saulys, How Spark is Making an Impact at Goldman Sachs, dans laquelle il explique que Spark a connu une adoption virale chez Goldman Sachs.

Performances
Spark est déjà connu pour être performant mais les développeurs de Databricks travaillent activement à améliorer encore les performances. Les optimisations sont souvent réalisées à un très bas niveau (structures mémoire, génération de bytecode, etc.) et le runtime pourrait, à terme, ne plus être la JVM (voir la keynote de Reynold Xin, A Look Ahead at Spark’s Development).


Notebooks
Bien que les notebooks aient des défauts (pas adapté au versioning de code…), ils sont très populaires chez les Data Scientists. Apache Zeppelin a notamment été très présent dans les talks. Les créateurs de ce notebook (NFLabs) disposaient d’ailleurs d’un stand.
Le notebook de Databricks - Databricks Cloud - a lui été montré plusieurs fois mais toujours par des employés de Databricks.
Nouveautés à venir
API des Datasets
Une nouveauté de Spark 1.6 sera l’API des Datasets. Les Datasets sont censés présenter une alternative entre le typage fort des RDD et la performance des Dataframes. Concrètement, on obtient un Dataset à partir d’un Dataframe et en lui appliquant une case class. On manipule alors le Dataset avec des opérations fortement typées et donc vérifiées par le compilateur.

Spark Streaming - Back pressure
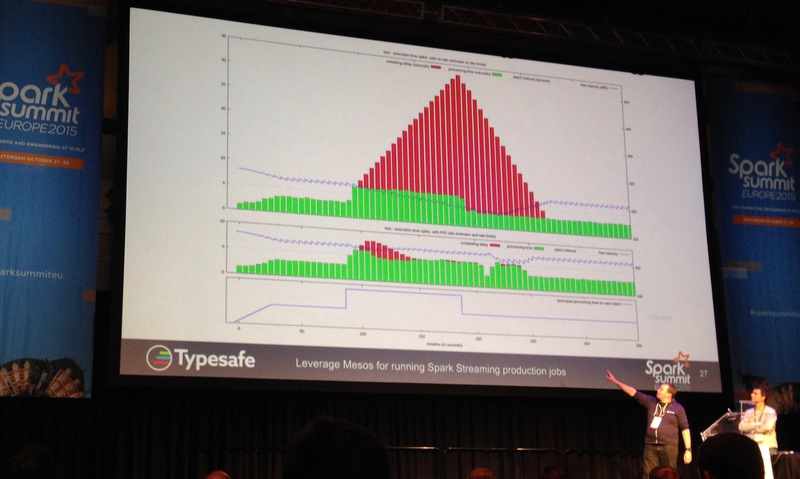
Spark Streaming étant de plus en plus utilisé, la question qui se pose le plus est celle du dimensionnement du cluster : il faut que le cluster Spark Streaming puisse traiter autant d’évènements qu’il en reçoit pour que la latence n’augmente pas en flèche (le risque est aussi que l’application crashe du fait d’une saturation mémoire).
Deux talks (Spark Streaming: Pushing the Throughput Limits, the Reactive Way et Leverage Mesos for running Spark Streaming production jobs) ont présenté la technique du Back pressure qui consiste à remonter au producteur d’évènements des informations pour qu’il ralentisse l’envoi de données. Cette technique repose sur des correcteurs PID et fonctionne notamment avec Kafka.

Conclusion
Ce Spark Summit était pour moi l’occasion de vérifier l’engouement de l’industrie pour Spark. Outre les applications Big Data, c’est bien la Data Science qui anime la communauté autour de Spark et qui rend le projet passionnant !
Comme indiqué plus haut, je reste mitigé vis-à-vis du format des talks (30 minutes) même si cela permet d’en voir beaucoup. Néanmoins, cet évènement apporte de nombreux enseignements sur les tendances actuelles et les discussions avec les professionnels du domaine étaient bien sûr très riches.
L’ensemble des talks sont disponibles en vidéo directement depuis la page du programme ou via les playlists sur Youtube.