Spark sur Google Compute Engine
Dans mon post Spark vs Command line tools, je comparais les performances de Spark et d’outils du shell pour traiter des résultats de parties d’échec. Le volume de données était très réduit (4,6 Go) et un seul nœud était utilisé. Spark étant un outil dédié au traitement distribué, l’exercice atteignait ses limites. Restait donc à étudier les performances sur des volumes plus importants et en cluster.
Détails de l’expérimentation
L’idée initiale était de dupliquer le jeu de données autant de fois que nécessaire pour répéter le benchmark sur 1,5 To de données réparties sur 5 machines. En préparant le test, j’ai réduit la cible à 230 Go (50 x 4,6 Go) car la copie de fichiers était très longue.
J’ai monté un cluster composé d’un master et de 5 workers sur Google Compute Engine (GCE). La configuration des machines était la suivante :
- VM de type n1-highcpu-4 : 4 processeurs virtuels et 3,6 Go de mémoire
- disque persistant de 200 Go sur le master et 400 Go sur les workers
- configuration logicielle : CentOS 7, Spark 1.2.0, Hadoop 2.6.0, Java 1.8.31
Pour le stockage des fichiers, j’ai utilisé HDFS. Toutefois, HDFS n’étant pas adapté au stockage de petits fichiers, j’ai aggrégé les 3025 fichiers en un seul de 4,6 Go.
Afin de respecter le principe de data locality :
- un nœud est à la fois master Spark et Namenode HDFS
- les autres nœuds sont à la fois des workers Spark et des Datanodes HDFS
Le code Spark utilisé est :
SparkConf conf = new SparkConf()
.setAppName("chess");
JavaSparkContext sc = new JavaSparkContext(conf);
sc.textFile(".../*.pgn")
.filter(line -> line.startsWith("[Result ") && line.contains("-"))
.map(res -> res.substring(res.indexOf("\"") + 1, res.indexOf("-")))
.filter(res -> res.equals("0") || res.equals("1") || res.equals("1/2"))
.countByValue()
.entrySet()
.stream()
.forEach(s -> System.out.println(s.getKey() + " -> " + s.getValue()));
La ligne de commande shell utilisée est :
$ time find . -type f -name '*.pgn' -print0 | xargs -0 -n4 -P4 mawk '/Result/ { split($0, a, "-"); res = substr(a[1], length(a[1]), 1); if (res == 1) white++; if (res == 0) black++; if (res == 2) draw++ } END { print white+black+draw, white, black, draw }' | mawk '{games += $1; white += $2; black += $3; draw += $4; } END { print games, white, black, draw }'
Les tests effectués
J’ai effectué des tests de performance en faisant varier plusieurs paramètres :
- Spark : avec 1 ou 5 workers
- Shell : sur un seul nœud
- jeu de données copié 1, 10 ou 50 fois, soit 4,6, 46 ou 230 Go de données
- stockage :
- sur HDFS en fichiers aggrégés (chaque fichier pèse 4,6 Go)
- sur disque local en fichiers aggrégés
- sur disque local en petits fichiers (les 3025 fichiers du jeu de données d’origine, éventuellement recopiés plusieurs fois)
Voici les résultats bruts obtenus :
| Expérimentation | Taille (Go) | Durée (s) | Débit (Mo/s) |
|---|---|---|---|
| Spark, 50 x 4,6 Go sur HDFS en fichiers aggrégés, 5 workers | 230 | 499 | 461 |
| Spark, 10 x 4,6 Go sur HDFS en fichiers aggrégés, 1 worker | 46 | 480 | 96 |
| Spark, 10 x 4,6 Go sur disque local en fichiers aggrégés, 1 worker | 46 | 468 | 98 |
| Spark, 1 x 4,6 Go sur disque local en fichiers aggrégés, 1 worker | 4,6 | 52 | 88 |
| Spark, 1 x 4,6 Go sur disque local en petits fichiers, 1 worker | 4,6 | 73 | 63 |
| Shell, 10 x 4,6 Go sur disque local en fichiers aggrégés | 46 | 593 | 78 |
| Shell, 1 x 4,6 Go sur disque local en fichiers aggrégés | 4,6 | 39 | 118 |
| Shell, 1 x 4,6 Go sur disque local en petits fichiers | 4,6 | 43 | 107 |
Analyse de la durée de traitement
Voici un graphe présentant les durées de traitement (less is better) :
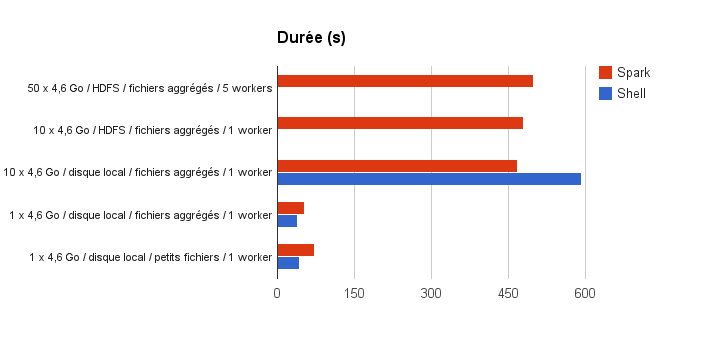
Analysons tout d’abord les tests sur disque local (sans HDFS). Sur 4,6 Go de données, les outils du Shell sont plus efficaces que Spark d’environ 30%. C’est ce que l’on avait constaté dans le post précédent. Toutefois, on note que Spark s’en sort un peu mieux avec un fichier aggrégé qu’avec de petits fichiers.
Lorsqu’on passe à 46 Go de données en local, Spark prend le dessus : le temps de traitement de Spark est multiplié par 9 (de 52 à 468 secondes) alors que celui du shell est multiplié par 15 (de 39 à 593 secondes). Spark montre qu’il scale linéairement quand le volume de données augmente, l’overhead potentiel du framework étant absorbé en augmentant le volume de données.
Au passage sur HDFS, les performances de Spark ne sont que légèrement impactées (de 468 à 480 secondes) ce qui est positif.
La constation la plus intéressante est effectuée lorsqu’on multiplie le volume de traitements et la puissance de calcul tous deux par 5 (passage de 1 à 5 workers et passage de 46 à 230 Go de données) : le temps de traitement reste quasi identique (de 480 à 499 secondes). La capacité à scaler horizontalement de Spark prend ici tout son sens : pour traiter plus de données, il “suffit” de rajouter des nœuds dans le cluster. Notons que, dans ce cas, il a été important de respecter la data locality pour éviter les I/O réseau.
Analyse du débit
Voici maintenant un graphe présentant les débits de traitement en Mo/s (more is better) :
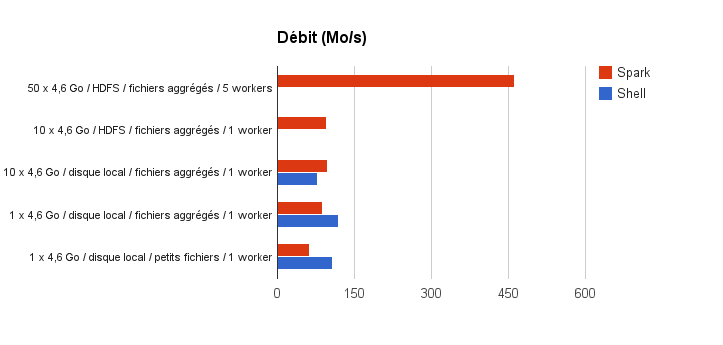
Observons d’abord les résultats sur un nœud. Lorsque le volume de données augmente, les outils du Shell perdent un peu en performance là où Spark se maintient. On remarque par ailleurs que le débit de traitement de Spark est presque identique que l’on traite 1 ou 10 fichiers, en local ou sur HDFS, dès lors que ces fichiers sont volumineux.
L’observation la plus intéressante est bien sûr le résultat avec 5 nœuds : le débit de traitement est presque multiplié par 5 (de 96 à 461 Mo/s) lors du passage de 1 à 5 workers. Augmenter le nombre de workers Spark permet bien d’augmenter le débit de traitement.
Conclusion
Si nous avions dû traiter 230 Go, voire 1,5 To, avec les outils du shell, le temps de traitement aurait explosé. Pour scaler horizontalement, nous aurions été obligé de répartir manuellement les données sur plusieurs machines et d’orchestrer, toujours manuellement, les traitements.
Avec Spark et HDFS, les choses sont beaucoup plus simples : une fois le cluster préparé, les données sont réparties automatiquement lorsqu’on les monte sur HDFS, et les traitements sont distribués par Spark sans modification de code.
Spark montre ici qu’il est très performant même lorsque le volume de données (230 Go) ne peut pas vraiment être qualifié de Big Data. Le framework adresse ainsi le problème de l’augmentation de la quantité de données à traiter par un scaling horizontal très facile à mettre en place.