Spark & Kafka - Achieving zero data-loss
Kafka and Spark Streaming are two technologies that fit well together. Both are distributed systems so as to handle heavy loads of data. Making sure you don’t lose data does not come out-of-the-box, though, and this post aims at helping you reach this goal.
TL;DR - Connect to Kafka using Spark’s Direct Stream approach and store offsets back to ZooKeeper (code provided below) - Don’t use Spark Checkpoints.
Overview of the problem
Spark Streaming can connect to Kafka using two approaches described in the Kafka Integration Guide. The first approach, which uses a receiver, is less than ideal in terms of parallelism, forcing you to create multiple DStreams to increase the throughput. As a matter of fact, most people tend to depreciate it in favor of the Direct Stream approach that appeared in Spark 1.3 (see the blog post on Databricks’ blog and a blog post of the main contributor).
The main problem we have to face when using the Direct Stream approach is making sure that we don’t lose messages when the application restarts after a crash or when we update the application. That is, we want to process each message at least once (messages must not be lost) and not at most once (messages can be lost).
Notice that, whatever you do, you might output the same result multiple times. Your output datastore must therefore either be idempotent (a second write does not modify what is stored) or you should be able to deal with duplicates in downstream jobs.
That being said, if you use the Direct Stream approach, you have 2 options to avoid data losses:
- Using checkpoints
- Keeping track of the offsets that have been processed.
When you read Spark’s documentation, checkpoints seem to be the way to go but they actually don’t come without their problems. Let’s first review why they are not a practical approach before describing an alternative one.
Spark Checkpoints
When you use the Direct Stream from Spark to Kafka, Spark uses Kafka’s simple consumer API and does not update the offsets in ZooKeeper, meaning that, when your application restarts, it will start consuming the topic from the end of the queue. Any message produced while the application was not running will not be processed.
Visually, your Spark job consumes messages from the queue and then stops (processed messages are marked as “o”, unprocessed ones as “O”):
Initial instance stops here
|
v
-------------
|o|o|o|o|O|O|------------------>
-------------
The new instance processes messages marked as “x” but leaves some unprocessed (“O”):
Initial instance stopped here
|
v
---------------------
|o|o|o|o|O|O|x|x|x|x|------------------>
---------------------
^
|
New instance starts here
Checkpoints are a way for Spark to store its current state and recover from this state when the application restarts.
The way checkpoints are implemented, you have to specify a directory on a file system where to write checkpoints. The file system should be shared between the nodes so that, if your node fails, another node can read the checkpoint. HDFS and S3 are valid options.
The first issue you will hit is that all your processing operations need to be Serializable. This is because Spark will not only store the state (Kafka offsets) but also serialize your DStream operations. This constraint can be particularly painful, especially when you depend on external libraries that were not implemented to be Serializable.
Assuming you have made your classes Serializable, the second issue you will hit is upgrading your application. Since Spark serializes your operations, if you start a new version of your application to read a checkpoint of the previous version, the following will happen:
- Either your application will start but will run the old version of the application (without letting you know!)
- Or you will get deserialization errors and your application will not start at all.
The answer to this is not to reuse checkpoints when upgrading the code. Instead, you will have to start a new instance in parallel of the first one before killing the first one.
First instance running alone
|
v
-------------
|o|o|o|o|O|O|-------------------------->
-------------
Then you spin up a second job that is will process from the end of the queue:
First instance running alone
|
v
-------------
|o|o|o|o|O|O|-------------------------->
-------------
^
|
Second instance ready to process from the end of the queue
Both instances process messages in parallel (they are marked as x). Notice that the first instance was able to catch up and process “O” messages (the second instance never read those).
First instance still processing new messages
|
v
---------------------
|o|o|o|o|o|o|x|x|x|x|------------------>
---------------------
^
|
Second instance processing new messages
You can then stop the first instance:
---------------------
|o|o|o|o|o|o|x|x|x|x|------------------>
---------------------
^
|
Second instance processing new messages alone
The biggest issue is of course that you will have duplicated outputs, reinforcing the need for an idempotent storage or the ability to deal with duplicates. The other issue is that you have to be very careful, when pushing upgrades, not to stop the previous version of your application too soon, otherwise you might leave some messages unprocessed.
Now, assuming you’re ok with all of this, you might hit a third issue with the checkpoints themselves: it takes time for Spark to prepare them and store them. In our case, we were only using metadata checkpointing, meaning our checkpoints were very small (~10kb). We were running a Spark Standalone cluster on AWS and the only shared file system we had available was S3. The issue was that the latency was very high - it took from 1 to 20 seconds to write a checkpoint, with an average of 2.6 seconds. It could have been caused by S3 itself or because we were using AES256 encryption, though the latter seems unlikely given the low volume of data to encrypt.
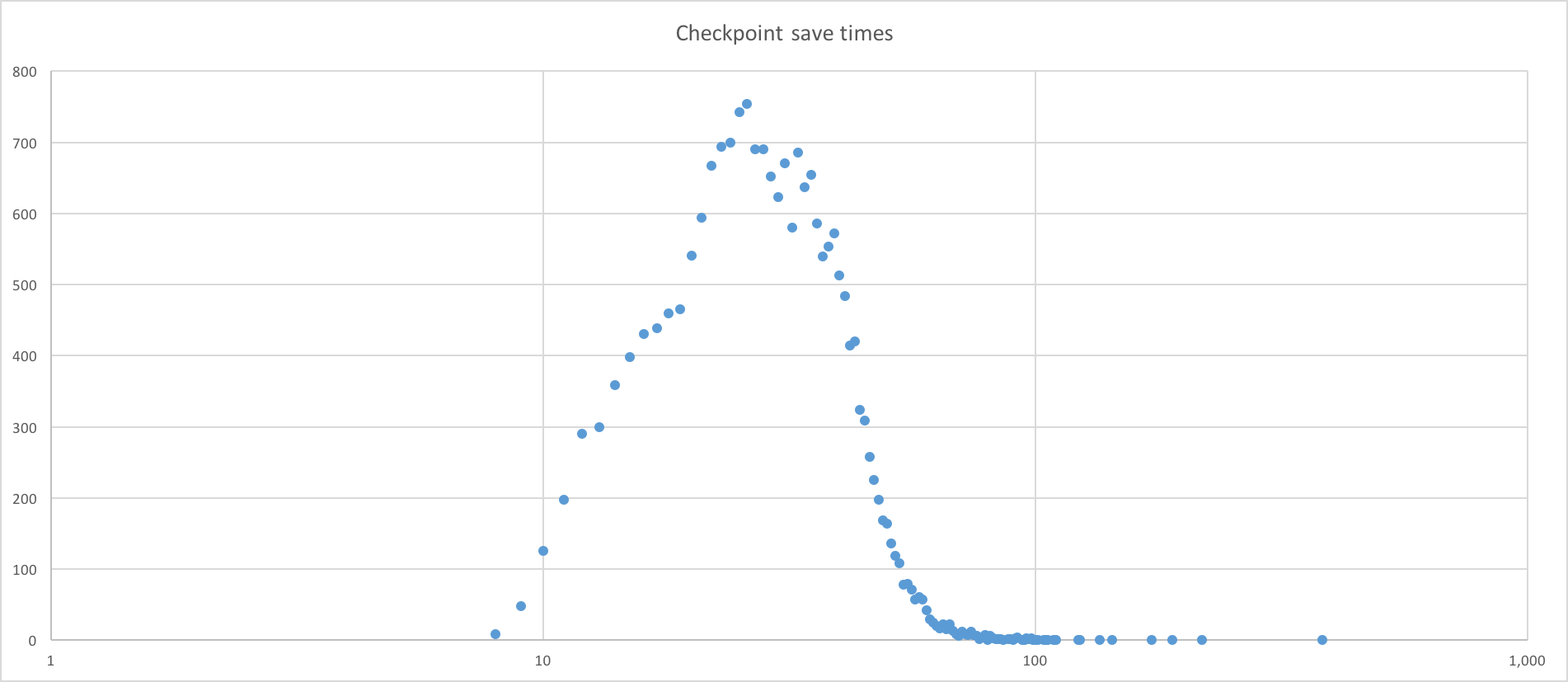
Write times from Spark to S3. This looks like a Gaussian distribution centered on 2.6 seconds (/!\ this is a logarithmic scale).
Given that you cannot decorrelate the batch interval of your Spark Streaming application (1 second in our case) and the write interval of the checkpoints, that means our checkpoints were backing up in memory, eventually causing the application to crash from an out of memory error. This issue was hard to find as we were not seeing it in development with checkpoints written straight to the disk. We had to attach a memory profiler and dig through a memory dump to find what was slowly eating memory (the application was crashing after an average of 22 hours).

We can see how I was able to identify the CheckpointWriter as being linked to a ThreadPoolExecutor, which was itself linked to the LinkedBlockingQueue that was responsible for the memory consumption.
I raised the problem on StackOverflow but couldn’t find anyone using S3 to write checkpoints. Since we didn’t have a HDFS file system on hand, and since checkpoints were overall quite painful, we decided to consider another approach: manually dealing with checkpoints.
Manually dealing with offsets
Here is the idea:
- Every time some messages get processed, store the Kafka offsets in a persistent storage.
- When starting the application, read the offsets to start from where you left off.
The first question is how to get the offsets from the DStream. You have to get the RDDs that compose the DStream and cast them to HasOffsetRanges so that you can access the offsetRanges property. This can be done through the tranform() or foreachRDD() methods.
The thing to know is that this has to be done immediately after creating the stream. Otherwise, the RDD might change types and it would no longer carry the offsets.
One thing to be careful about is not storing the offsets too soon. Since you are retrieving the offsets before actually processing the messages, this is too early to store the consumed offsets. If you stored them immediately and the application crashed, you would lose the messages that were about to be processed.
The good way to do it is to store the beginning offsets (fromOffset property) at the beginning of the batch, not the end offsets (untilOffset property). The only risk is to have successfully processed a batch but not updated the offsets, in which case you would reprocess the messages while it’s not needed. But again, you should deal with duplicates down the stream.
Here is how I write it in Scala:
def kafkaStream(...): InputDStream[(String, String)] = {
...
kafkaStream.foreachRDD(rdd => saveOffsets(..., rdd))
...
}
private def saveOffsets(..., rdd: RDD[_]): Unit = {
...
val offsetsRanges = rdd.asInstanceOf[HasOffsetRanges].offsetRanges
val offsetsRangesStr = offsetsRanges.map(offsetRange => s"${offsetRange.partition}:${offsetRange.fromOffset}")
.mkString(",")
ZkUtils.updatePersistentPath(zkClient, zkPath, offsetsRangesStr)
...
}
Then comes the question of restarting the application from the saved offsets. All you have to do is read the offsets and call an overload of the createDirectStream() method to pass it the offsets:
def kafkaStream(...): InputDStream[(String, String)] = {
...
val storedOffsets = readOffsets(...)
val kafkaStream = storedOffsets match {
case None =>
// start from the latest offsets
KafkaUtils.createDirectStream[String, String, StringDecoder, StringDecoder](ssc, kafkaParams, topics)
case Some(fromOffsets) =>
// start from previously saved offsets
val messageHandler = (mmd: MessageAndMetadata[String, String]) => (mmd.key, mmd.message)
KafkaUtils.createDirectStream[String, String, StringDecoder, StringDecoder,
(String, String)](ssc, kafkaParams, fromOffsets, messageHandler)
}
...
}
private def readOffsets(...): Option[Map[TopicAndPartition, Long]] = {
...
}
Writing the offsets to ZooKeeper
So now comes the question of where to store the offsets. The datastore you choose should be distributed and always accessible so that any Spark node can access despite failures.
ZooKeeper is a good option. It is a distributed datastore that is designed to store small values reliably. Any write operation you perform will be done in a transaction against the ZooKeeper cluster. And since we’re only storing offsets, the value we will store will be very small.
One thing with ZooKeeper, though, is that it is not a high-throughput datastore. It’s fine in this case, though, since we only need to write the offsets once for each batch, i.e. every second at most.
So now come the implementation details. Two things to note:
- We are using the
foreachRDD()method and return the initial DStream so that you can apply any operation to it. The way Spark works, it will not move to the next batch until all the operations on a batch are completed. This means, if your operations takes longer than the batch interval to process, the next offsets saving operation will not kick in before the previous batch has completed. You’re safe. - We used the same ZooKeeper client library that Kafka is using. That way, we don’t have to pull another dependency.
- We are creating a single instance of the ZooKeeper client. Since the
foreachRDD()method is executed in the Driver of the Spark application, it is not going to be serialized and sent to the Workers. - We are writing a single string containing the offsets per partition. It looks like
partition1:offset1,partition2:offset2,..., meaning a single write is enough per Spark Streaming batch.
When your application is running, you should see logs similar to the following appearing for every batch:
2016-05-04 14:11:29,004 INFO - Saving offsets to Zookeeper
2016-05-04 14:11:29,004 DEBUG - OffsetRange(topic: 'DETECTION_OUTPUT', partition: 0, range: [38114984 -> 38114984])
2016-05-04 14:11:29,005 DEBUG - OffsetRange(topic: 'DETECTION_OUTPUT', partition: 1, range: [38115057 -> 38115057])
2016-05-04 14:11:29,022 INFO - Done updating offsets in Zookeeper. Took 18 ms
Then, if you restart the application, you should see the following logs:
2016-05-04 14:12:29,744 INFO - Reading offsets from Zookeeper
2016-05-04 14:12:29,842 DEBUG - Read offset ranges: 0:38114984,1:38115057
2016-05-04 14:12:29,845 INFO - Done reading offsets from Zookeeper. Took 100 ms
So far, this code has proved to be reliable and I’m happy to share it with you on GitHub!
EDIT - Our application recovered gracefully from a network outage!
Earlier this week, we had a network outage that broke the connection between Spark and Kafka:
2016-05-10 00:58:01,384 ERROR [org.apache.spark.streaming.kafka.DirectKafkaInputDStream] ... java.io.IOException: Connection reset by peer...
In the previous batch before that happened, the offsets had been saved to ZooKeeper:
2016-05-10 00:56:59,155 INFO ... - Saving offsets to Zookeeper
2016-05-10 00:56:59,156 DEBUG ... - Using OffsetRange(topic: 'AUTH_STREAM.JSON', partition: 3, range: [183975213 -> 183975252])
2016-05-10 00:56:59,156 DEBUG ... - Using OffsetRange(topic: 'AUTH_STREAM.JSON', partition: 0, range: [183779841 -> 183779894])
...
2016-05-10 00:56:59,157 INFO ... - Done updating offsets in Zookeeper. Took 1 ms
Because of the exception above, the application died. It was automatically restarted by the Spark Master since we’re using the supervised mode. When the application restarted, it was able to read the offsets from ZooKeeper:
2016-05-10 00:59:24,908 INFO ... - Reading offsets from Zookeeper
2016-05-10 00:59:25,101 DEBUG ... - Read offset ranges: 3:183975213,0:183779841,...
2016-05-10 00:59:25,107 INFO ... - Done reading offsets from Zookeeper. Took 198 ms
The application then smoothly processed the events that had been accumulating in Kafka while the network was down, and this happened without requiring any manual intervention. A good proof of the resilience of the system!